基于溯源图的细粒度 APT 检测
项目描述
- 基于溯源图的细粒度 APT 检测系统(包含的模块如下)
- 1 溯源图建立(包括善意、恶意节点)
- 2 向量模型训练(对进程/文件节点分别用
FastText训练模型)
- 3 权重与稳定性计算(进程集的平均词向量节点的重要程度分析)
- 4 异常时别模型训练(三层变分自编码器)
具体实现
- 1 溯源图建立(包括善意、恶意节点)
- 节点主要三种类型:网络传输、文件操作、进程操作(但是这三种都伴有进程)
- 溯源图格式:
- 进程为核心节点
- 前驱是父进程节点
- 后继是网络映射节点和文件节点
- 节点格式:图节点是一个大型字典,里面是一个个的键值对
- 键:能唯一标识节点的 md5
- (同一个父进程只生成一个节点,当前的操作进程可生成多个节点)
- 值:是一个小字典,存储了节点中的有价值信息、其前驱后继分别是什么
- 节点类型:
- 进程节点:父进程、本进程、父进程指向本进程的边
- 文件节点:本进程、文件、本进程指向文件的边
- 网络节点:操作本次网络操作的进程、网络操作的映射、进程指向映射的边
- 2 向量模型训练(针对文件名/进程名分别训练两个
FastText模型)
- 2.1 数据清洗:去掉 ascii 字符、去掉多余字符、以标点符号为分割、转小写,存入列表
- 2.2
FastText模型训练,得到两个模型分别处理文件名/进程
- 3 计算权重(溯源图:转为词向量、计算相似度、超阈值合并)
- 3.1 文件独特性计算(tf-idf 高:全局稀有、部分频繁)**这里逻辑有问题,后面看代码补充**
- (tf-idf 越高代表文件越独特,越可能有价值,这里有待考量)
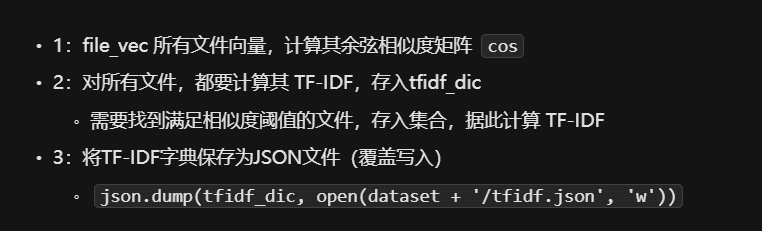
- 3.2 进程和本进程所有后继的词向量的均值计算(因为进程的后继是文件&网络映射节点)
* 计算方式:
+ 1 进程本节点用训练好的进程`FastText`模型计算
+ 2 进程后继的文件&网络映射节点用训练好的文件`FastText`模型计算
+ 3 暂存本进程集的所有词向量
+ 4 进行权重配比(不同的文件向量应该有不同的重要性权重)
- 进程节点 向量`r * tfidf`均值
- 后继节点
* `tfidf`列表中有的`r * tfidf`记录值
* `tfidf`列表中没有的`r * tfidf`均值
+ 5 求本进程的平均权重
- 3.3 稳定性计算:计算同一个`Pname`下的多个平均词向量稳定性(一个 Pname 可能对应多个进程集)
* (因为进程节点唯一标识符是 `md5(Pname+Pid)`)
* `clustering = DBSCAN(eps=0.05, metric='cosine', min_samples=5).fit(refer_words)`
* DBSCAN 聚类:使用余弦相似度、邻域范围、邻域内样本数
+ <font style="color:#E4495B;">分类簇数 s</font>:作为稳定性衡量标准
- 簇数多:一个 Pname 的行为模式很多,即它不稳定
- 所以稳定性分数 s 越高,越不稳定(<font style="color:#E4495B;">簇数越多,越可能有恶意行为</font>)
- 4 模型训练:使用三层变分自编码器 VAE
- (输入还原,根据重建率,判断异常模块)
- 构造函数
def __init__(self,latent_dims)一些预定义
- 输入最后转换为latent_dims 维度的向量
- 对nn.Linear类实例化4个全连接层:
- nn.Linear是对输入张量的线性变换,即y=Wx+b,其中W是权重矩阵,b是偏置向量,x是输入向量,y是输出向量
- 定义标准正态分布的对象
self.N = torch.distributions.Normal(0,1)
- 定义散度计算结果
self.kl
- 衡量潜在变量的分布与标准正态分布间差异(希望将潜在空间的分布接近标准正态分布)
- 向前传播函数
forward(self,x)
- 将输入
x 转化为潜在空间的概率分布,并从该分布中采样得到潜在变量 z